Note
Go to the end to download the full example code.
Tiled aggregation from points with Dask
Group points into grid cells in a tiled manner, using Dask.
Introduction
In example aggregate.py an approach is demonstrated where points are grouped in cells and averaged per cell. This example does the same, but in a tiled manner. Dask is used for the groupby opertaion instead of Pandas. The main difference is that Dask divides the data into chunks that can be processed independently. This approach is beneficial if data does not comfortably fit into memory. A second reason to use this approach is the ability to process different chunks concurrently, which can provide a significant speedup.
Note
Even though parallel processing using Dask can speed up the script, for a small case like this the overhead is larger than the benefit obtained by parallelizing the operation.
For a description of the approach used, please refer to aggregate.py. This example mostly highlights the differences between the two approaches.
Note
Dask uses the terms ‘chunks’, ‘blocks’ and ‘partitions’. While there are some nuances, in this example these terms will be used interchangeably. I will try to stick with ‘chunks’ where I can since this is the general term, though you will find references to ‘map_blocks()’ for Arrays and ‘map_partitions()’ for DataFrames.
Generate input data
Let’s start by generating some points.
The data will be a set of points scattered around a circle to create
a dougnut-like shape.
I will first generate the points and the turn them into a Dask Array
using dask.dataframe.from_array.
In a scenario where Dask is used because the data is large and memory is limited,
you will likely obtain your dask array in a way that
does not involve first loading the whole array into memory like I do here.
I will print npartitions to show the number of chunks the array is divided in
(spoiler, it will be 2000/500 = 4).
import dask
import dask.array
import dask.dataframe
import numpy
from gridkit.doc_utils import generate_2d_scatter_doughnut, plot_polygons
points = generate_2d_scatter_doughnut(num_points=2000, radius=4)
df = dask.dataframe.from_array(points, columns=["pnt_x", "pnt_y"], chunksize=500)
print(df.npartitions) # show the number of chunks
4
Relate points to grid cells
Now we can create a grid and determine the cell associated to each point.
No advanced knowledge of Dask is required to follow this example.
It suffices to know that ‘map_blocks’ and ‘map_partitions’ will apply the supplied function to all chunks.
GridIndex.index_1d() is used because it gives a single number that can be used as
a DataFrame index during the groupby operation.
The column ‘nr_points’ will contain the nr of points per cell once ‘.count()’ is called on the groupy object
Note
The DataFrame only has a ‘pnt_x’ and a ‘pnt_y’ column. which is already the appropriate
shape for grid.cell_at_point. However, p[["pnt_x", "pnt_y"]] is specified here
to make clear that cell_at_point expects this pattern and any other columns in the
DataFrame will need to be ignored for this operation.
from gridkit import GridIndex, HexGrid
grid = HexGrid(size=1, shape="flat")
def index_1d_at_point(df):
"""Find the cell for each point in the dataframe and return the 1D index.
This operation is meant to map to each DataFrame partition
"""
return grid.cell_at_point(df[["pnt_x", "pnt_y"]]).index_1d
df["cell_id"] = df.map_partitions(index_1d_at_point)
df["nr_points"] = 1
print(df)
Dask DataFrame Structure:
pnt_x pnt_y cell_id nr_points
npartitions=4
0 float64 float64 int64 int64
500 ... ... ... ...
1000 ... ... ... ...
1500 ... ... ... ...
1999 ... ... ... ...
Dask Name: assign, 5 expressions
Expr=Assign(frame=Assign(frame=FromArray(07a2aa7)))
We can group by the ‘cell_id’. That means points with the same ‘cell_id’ will be combined. ‘count()’ then gets the number of points for every ‘cell_id’.
grouped = df.groupby("cell_id")
occurrences = grouped.count()
Now we have the number of points per cell.
In order to get the Polygon of each corresponding cell,
‘occurrences.index’ can be used, but since it is a 1d index,
it first needs to be converted to a normal index using GridIndex.from_index_1d()
Note
If you are wondering why we went through all that effort just to end up with a pandas DataFrame in the end, suffice it to say that the size of the data is significantly reduced after the groupby. Also, for the sake of the example I will plot the data with matplotlib.
def shapely_geom_from_index_1d(id_1d):
"""Generate the Shapely geometry for each 1D index.
This operation is meant to map to each DataFrame partition
"""
return numpy.array(grid.to_shapely(GridIndex.from_index_1d(id_1d)).geoms)
polygons = occurrences.index.map_partitions(shapely_geom_from_index_1d)
geoms, points_per_cell = dask.compute(polygons, occurrences.nr_points)
/tmp/gridkit_docs/v1.0.1/gridkit-py/venv/lib/python3.10/site-packages/dask/_expr.py:1260: UserWarning: Computing mixed collections that are backed by HighlevelGraphs/dicts and Expressions. This forces Expressions to be materialized. It is recommended to use only one type and separate the dask.compute calls if necessary.
warnings.warn(
Visualize the results
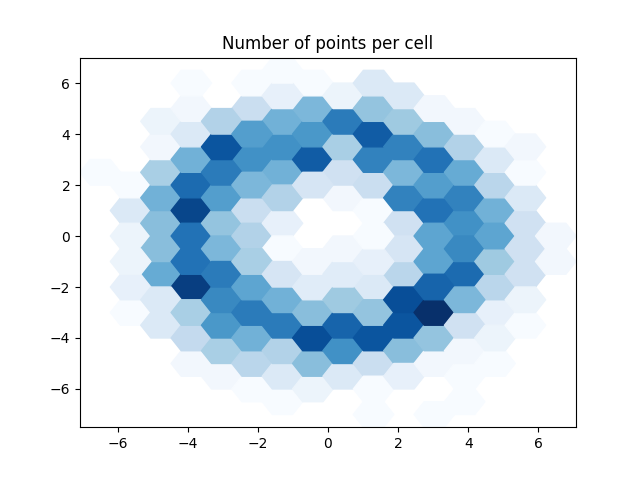
Note how the results are identical to the pandas version. The input data was the same so this should indeed be the case.
import matplotlib.pyplot as plt
plot_polygons(geoms, points_per_cell, "Blues")
plt.title("Number of points per cell")
plt.show()
Total running time of the script: (0 minutes 0.415 seconds)